※この記事はASCII.jpからの転載です(文中リンクはASCII.jpの記事に飛ぶことがあります)
今回は米国時間の10月8日に発表会が開催されたZen 3ことRyzen 5000シリーズの話である。すでにハッチパイセンの速報が上がっているのでお読みの方も多いだろう。
発表会のビデオそのものはこちらから見直すことができるが、これに先立ってもう少し細かな情報も得られたので、これをベースにRyzen 5000シリーズを解説していこう。

Zen 3マイクロアーキテクチャー
まずはZen 3の中身についてだが、最初にお断りしておくと、AMDは現時点でZen 3で利用されるプロセスの詳細を明らかにしておらず、“7nmプロセス”とだけ説明している。連載553回で説明したように、AMDのいう7nmプロセスにはN7/N7P/N7+/N6がある。
筆者はZen 3世代はN7+プロセスに移行したと見ているが(理由は後述)、確証はない。ちなみTSMCは、N7→N7+ではトランジスタ密度が1.2倍になり、同一周波数なら消費電力15%減、同一消費電力なら動作周波数が10%向上するとしており、これらのパラメーターも今回のZen 3の製品スペックにマッチしたものになっている。
さて内部であるが、Zen 3コアは、IPCの大幅な改善が行なわれたとする。具体的には19%のIPC改善があった、というのがAMDの説明である。

IPCを大幅に改善したZen 3コア。コアレイアウトの変更やキャッシュトポロジーの変更もIPC改善の一部な気もするのだが、このあたりの切り分けはよくわからない
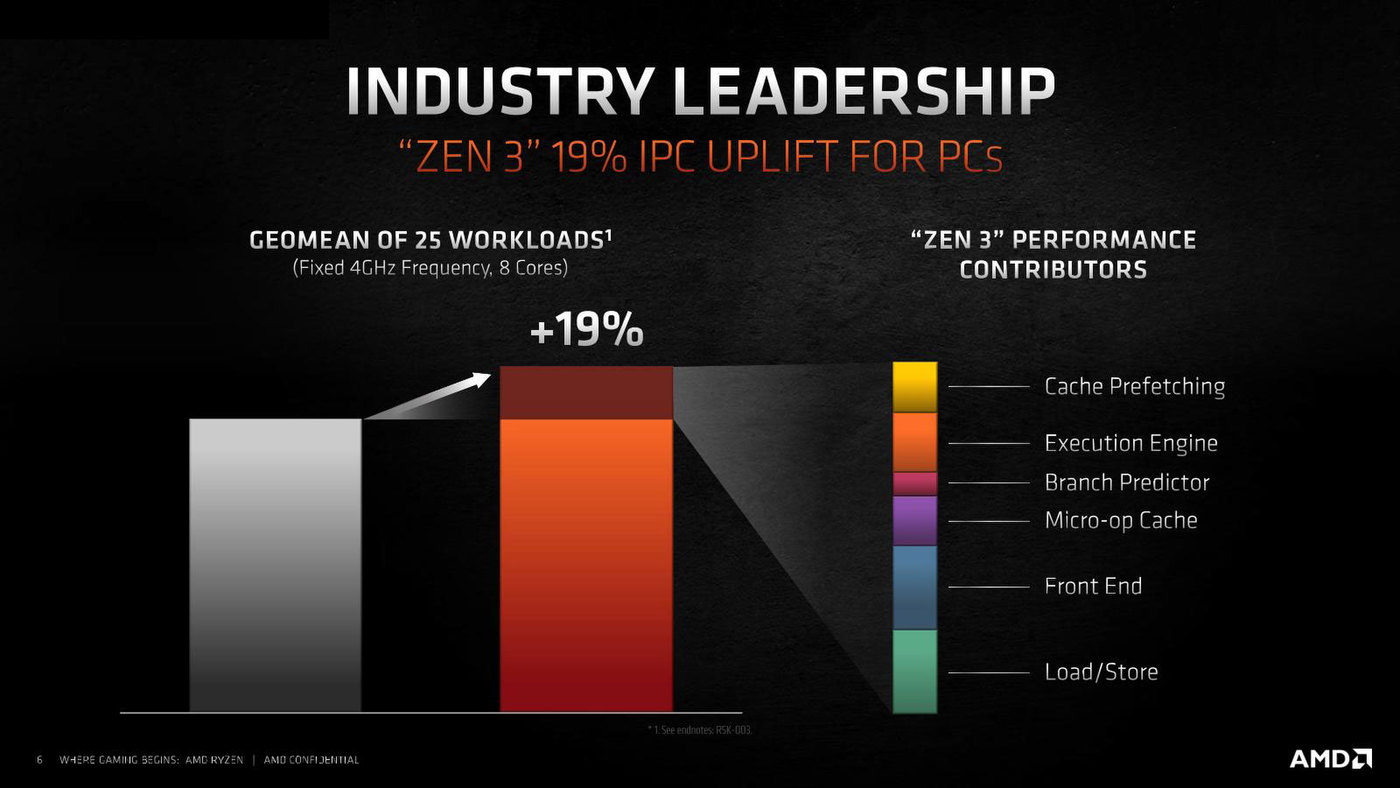
IPCの内訳。フロントエンドの向上とExecution Engineの向上が結構大きな比率を占めている
これだけだと今ひとつわからないのだが、発表会におけるPapermaster氏の説明で、もう少し細かいことがわかった。

Papermaster氏の説明は一瞬なので、見逃しやすい。発表会のビデオで言えば、ちょうど10分あたりである
デコード/イシューを拡張し
バックエンドを強化
「Wider Issue in Float and Int Engine」とあるので、バックエンドを強化したことがわかる。Zen 2世代の内部構造は連載516回で説明したが、バックエンドはALU 7way/FPU 4wayというけっこう強力なものだった。

連載516回で説明したZen 2世代の内部構造
これをさらに強化するということなので、おそらくはALU(整数演算器)が8wayないし9way、FPU(浮動小数点演算器)は4wayの対称型、もしくは6wayの非対称型になったものと思われる。
まずALU側だが、もともとZen 2でもALU×4+AGU(アドレス生成ユニット)×3という強烈な構成になっていた。これをさらに引き上げたというのだから、ALU×5+AGU×3ないし×4になった、と見なすのが妥当だろう。
一方のFPU。少し古い話であるが、もともとZenには4つの128bit FPUがあり、AVX命令を扱う場合はこれを2つづつペアにして256bit命令を実行する形になっているが、問題はこのFPUが完全に対称になっておらず、256bit命令を1サイクルあたり1命令しか扱えないという制約があった(詳細は連載333回を参照)。
この制約はZen 2で、FPUの幅を256bitに拡張してだいぶ緩和された。ただし非対称構成はそのままである。
今回、FPUに関しても“Wider Issue”というからには、FPUの数を6つ(ただし依然として非対称のまま)にしたか、それともFPUの数は4つのままながら完全対称型にすることで、実質的なイシュー数を増やしたかのどちらかだと考えられる。エリアサイズを考えると後者な気がするが確証はない。
実のところ、今後もインテルと競争していく以上、IPCを引き上げるためにはさらにデコード/イシューを広げる必要があるのは間違いない。インテルのSunny CoveはALU×4構成であるが、続くWillow Coveはともかくその次のGolden CoveはさらにIPCを引き上げると言っている以上、ALU×5は見えており、これを先取りする形でAMDがZen 3をALU×5にするのは不思議でもなんでもない。これが冒頭で示したIPCの内訳画像にある“Execution Engine”の分だと思われる。
おそらくはデコード段も、従来の4命令/サイクルから5命令/サイクルに拡張している。これはすでにインテルがSunny Coveで実現している話であり、まったく不思議ではない。というか、実行ユニットがさらに拡張されるとなると、当然デコードもこれに合わせて同時デコード数を広げないと実行ユニットが遊んでしまうことになる。ここの拡張は当然であろう。これが“フロントエンド”の分と思われる。
Micro-opキャッシュの帯域を強化
Micro-opキャッシュも、当然幅を広げることになる。再びZen 2世代の内部構造に戻るが、Zen 2までは4 x86命令/サイクル(≒4~8 Micro-ops/サイクル。おそらく平均的には5~6 Micro-ops/サイクル)でデコードから命令が供給されるが、Micro-opキャッシュに入っている場合はこちらから優先的にMicro-opが供給される。
これが6 Micro-ops/サイクルという帯域だった。ただ今回イシュー数が増えており、これに合わせておそらくMicro-Opキャッシュの帯域も7ないし8 Micro-op/サイクルに強化されたと思われる。
また、帯域が増えたら当然その分容量も増やさないといけないが、これらは必然的に性能の改善につながることになる。冒頭で示したIPCの内訳画像でMicro-opキャッシュにあたるのがこれだろう。






