※この記事はASCII.jpからの転載です(文中リンクはASCII.jpの記事に飛ぶことがあります)
1)GPUにもLLCを搭載する「Infinity Cache」
Ryzenの躍進の1つはコア数と価格のバランスが優れていることだが、もうひとつ大容量L3キャッシュの存在も忘れることはできない。特にRyzen 5000シリーズはコアあたりのL3キャッシュ量を倍にすることで、レイテンシーを削減しさらに性能を伸ばすことに成功した。
そして今回、Radeon RX 6000シリーズの新要素である「Infinity Cache」は、GPU用のLLC(Last Level Cache)というべきものだ。
先代Radeon RX 5000シリーズのキャッシュでは、レイテンシーが低い反面、キャッシュのヒットミスが大きかったという(AMD談)。これを改善するには新たなキャッシュを載せるのが一番だ。すでにAMDはEPYCで広帯域かつ大容量なキャッシュを扱う経験を積んでおり、これをGPUに転用したというわけだ。
Radeon RX 6000シリーズのInfinity Cacheは128MBで、Infinity FabricによってGPUに接続される。Infinity Cacheは256bit幅のGDDR6メモリーとほぼ同等の帯域をもたらすが、メモリーコントローラーを増やし512bit幅にするよりも消費電力は少なく、かつフットプリントをコンパクトにできる。AMDの技術をフル活用して生まれたAMDらしい新機能といえるだろう。

AMDの資料より抜粋。RX 5000シリーズではL0~L2までのキャッシュが存在したが、ヒットレートの悪さが欠点
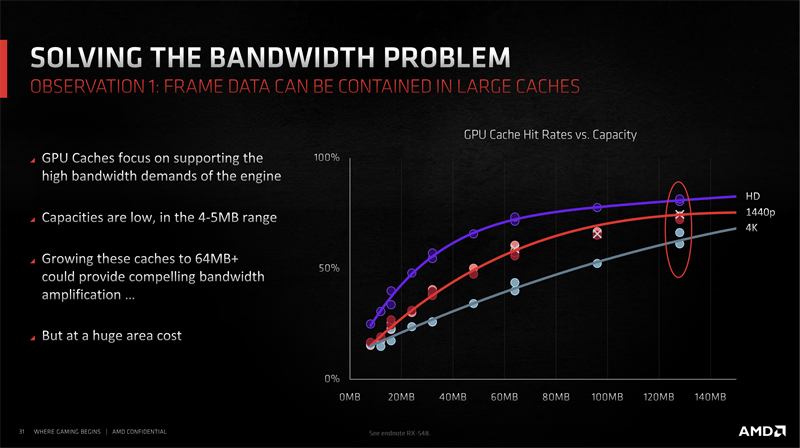
キャッシュ搭載量とヒット率の関係。キャッシュが4MB程度(左端)だとフルHDでヒット率は25%程度にしかならないが、キャッシュ64MBでヒット率70%前後が見込める。キャッシュは搭載すればするだけヒット率が改善することが見込めるが、それにはキャッシュ回路のフットプリントが問題
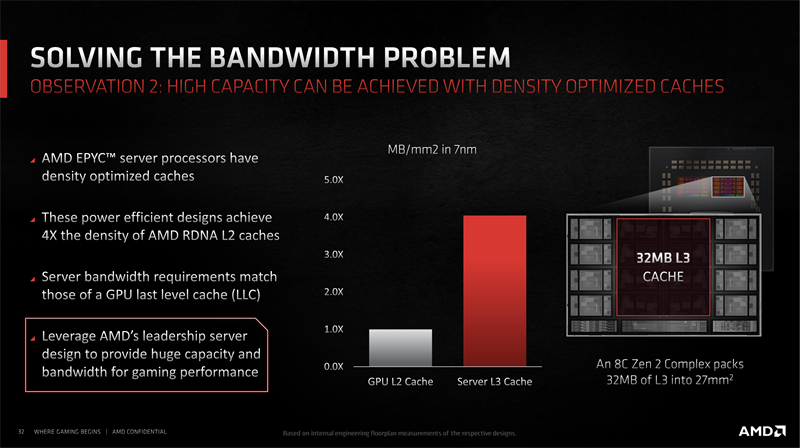
キャッシュのフットプリント問題を解決したのは、EPYCに実装した巨大なL3キャッシュ。RX 5000シリーズのL2の4倍の密度で実装しており、さらにゲームのパフォーマンスを支えられるだけの接続技術も培っていたという話

Infinity FabricでGPUとInfinity Cacheを接続することで、256bit幅のメモリー帯域に匹敵する帯域が得られた。このInfinity Fabricは負荷によってクロックを変動させることで消費電力を抑制する。高負荷時は最大1.94GHzで動作し、550GB/secの帯域が得られる
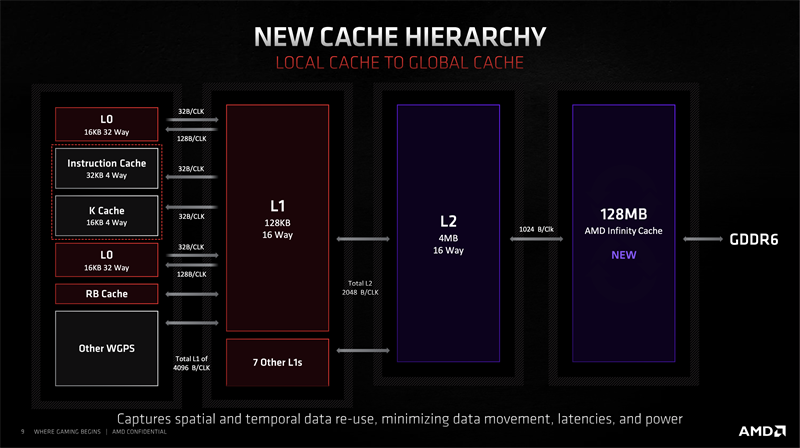
Radeon RX 6000シリーズのキャッシュ階層。128MBのInfinity Cache(LLC)を設けることで、データの移動を最小限に抑える。これはレンダーレイテンシーや消費電力の削減につながる
2) CPU→VRAMのデータ転送を効率化する「Smart Access Memory」
「Smart Access Memory」、略して“SAM”は、Infinity Cacheに並ぶRX 6000シリーズ独自の新機能だ。 これまでCPUからビデオカード上のVRAMへ描画に必要なデータを送る場合、歴史的経緯(32bit OSとの互換性確保)から256MB単位のアクセスに制限されていた。
だがVRAM消費量が4GBや6GBの時代ならまだしも、10GB超も現実になった今、256MB単位でチマチマと転送をかけるのは非効率的であり、この処理そのものがボトルネックの1つになる。
そこでSAMを使うことでVRAMのメモリー空間全てにサイズ制限なくCPUからアクセスできるようになるため、多量のデータをVRAMにより効率良く転送できるというものだ。

AMDの資料より抜粋。既存のシステムではCPUからVRAMへデータを転送する場合、256MBの小さな領域単位でしかアクセスできなかった

SAMを利用すればVRAMの好きな領域に好きなサイズでアクセスできるため、ここのオーバーヘッドが解消される
すでにRadeon 5000シリーズの時に解説した通り、SAMを使うにはRyzen 5000シリーズと500シリーズチップセット(X570およびB550)、そしてRX 6000シリーズの3つをセットにする必要がある。当初PCI Express Gen4に依存する何かを使っているのではと思われていたが、実際には「リサイズ可能なBAR(Base Address Register)」を利用したものだ。
これはマザーボード側のBIOSで有効化する機能であり、Ryzen 5000シリーズのBIOSにはすでに組み込まれている。このBIOS上で「Above 4G Decoding」と「Re-Size BAR Support」を有効にし、さらに「CSM Support」を無効化しUEFIブートすることがSAMを有効化するうえでの必須要件となる。SAMを使うには特にゲーム側で対応は必要がないが、逆に不具合を起こす可能性も否定できない。
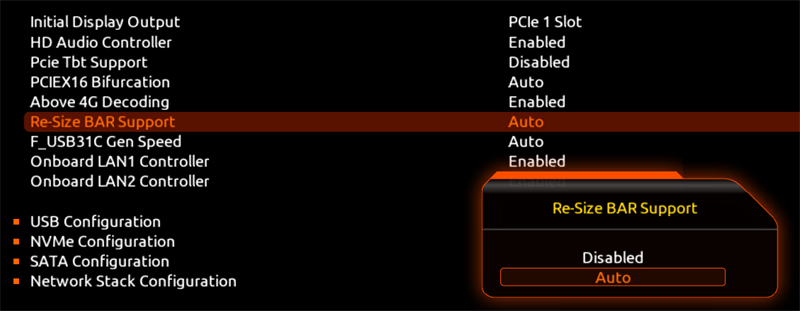
Radeon RX 6000シリーズのSAMを有効にするには、マザーボードのBIOS上で「Above 4G Decoding」と「Re-Size BAR Support」の2つを有効またはAutoにする必要がある。このマザーボードでは2つの項目を別個に設定できたが、Above 4G Decodingを有効にしないとRe-Size BAR Supportが変更にできないマザーボードもある

Re-Size BAR Supportを有効にしたうえで、CSM Supportを切ってUEFIブートにすることが、SAMを使う上での必要な設定となる

Re-Size BAR Supportを有効にしていない状態でビデオカードのプロパティーを見るとこういう表示になる。試しに一番上に出ているメモリーの範囲を計算すると、268435455バイト、つまり256MiBとなる
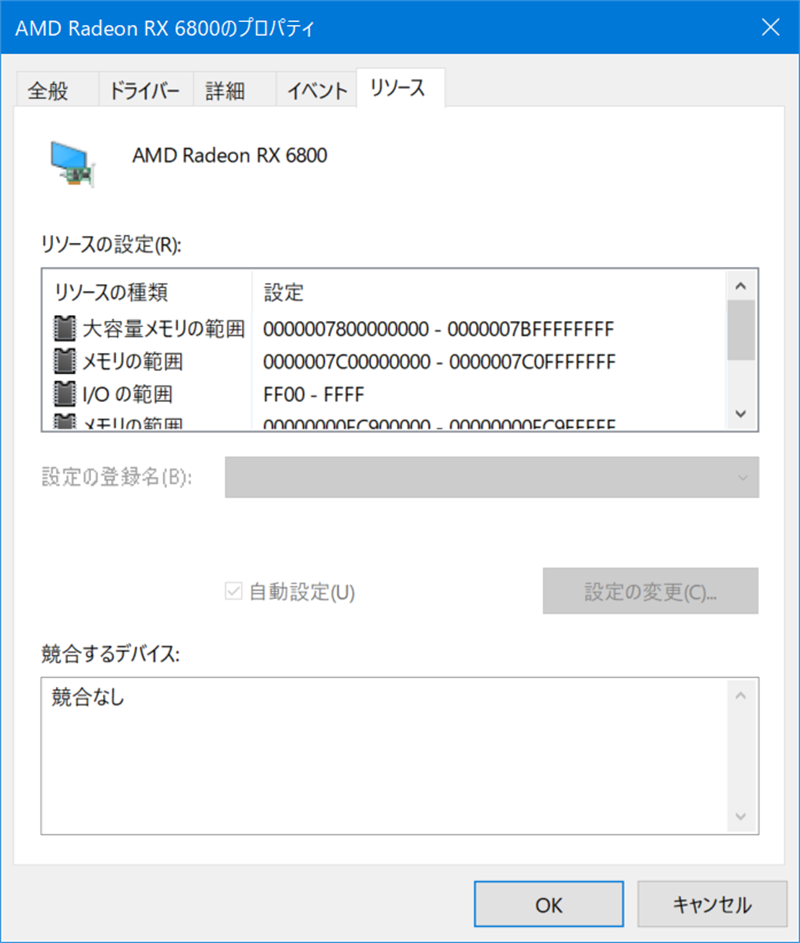
Re-Size BAR Supportを有効にしてから開くと「大容量メモリの範囲」という項目が出現する。この範囲をGiB単位に直すと16GiBとなる
SAMそのものはガチガチのAMD縛りな機能ではない。PCI Expressの規格に存在したが、互換性確保という歴史的経緯からずっと有効活用されずに放置されてきた機能を利用したものなのだ。ハードウェアの条件から何か特殊な仕掛けをAMDが作り込んできたのではと予想していたが、実はPCI Expressの規格を使っただけに過ぎない。
SAMが特殊な仕掛けを必要としない機能ならば、AMDが指定する組み合わせ以外でもSAMは実現可能なはずである。これについては先日、NVIDIAよりメディアに向け以下のような情報が送付されている。該当部分だけ抜粋しよう。

NVIDIAから送られてきた情報のうち、SAMに関連する部分の抜粋
これによればNVIDIAもSAM相当の機能をRTX 30シリーズに実装すべく開発を進めており、その機能を有効化するとSAMと同様に描画性能が向上すると述べている。実際にどれだけ伸びるとは書いてないので安易に喜ぶのは禁物だが、AMDのSAMが業界を動かしたのだから、喜ばしいといえるだろう。
NVIDIAがこの機能に先鞭を付けられなかったのは、ひとえにマザーボードメーカーとの協業が必須であり、必然的にチップセットを握っているAMDに話を持ちかけざるを得ないからだろう。素人目にもそれは無理だろうとわかる話ではあるので、プラットフォーム全体を手がけられるAMDが先に手をつけたのはごく自然の流れではないだろうか。






