※この記事はASCII.jpからの転載です(文中リンクはASCII.jpの記事に飛ぶことがあります)
19%のIPC向上は
ユニファイドL3キャッシュの効果が大きい
こうした結果が、平均19%のIPC向上という結果だという。その19%の内訳が連載584回の画像になるわけだが、この中で見えない部分はCache Prefetchingくらいのもので、あとはおおむね納得できるものとなっている。
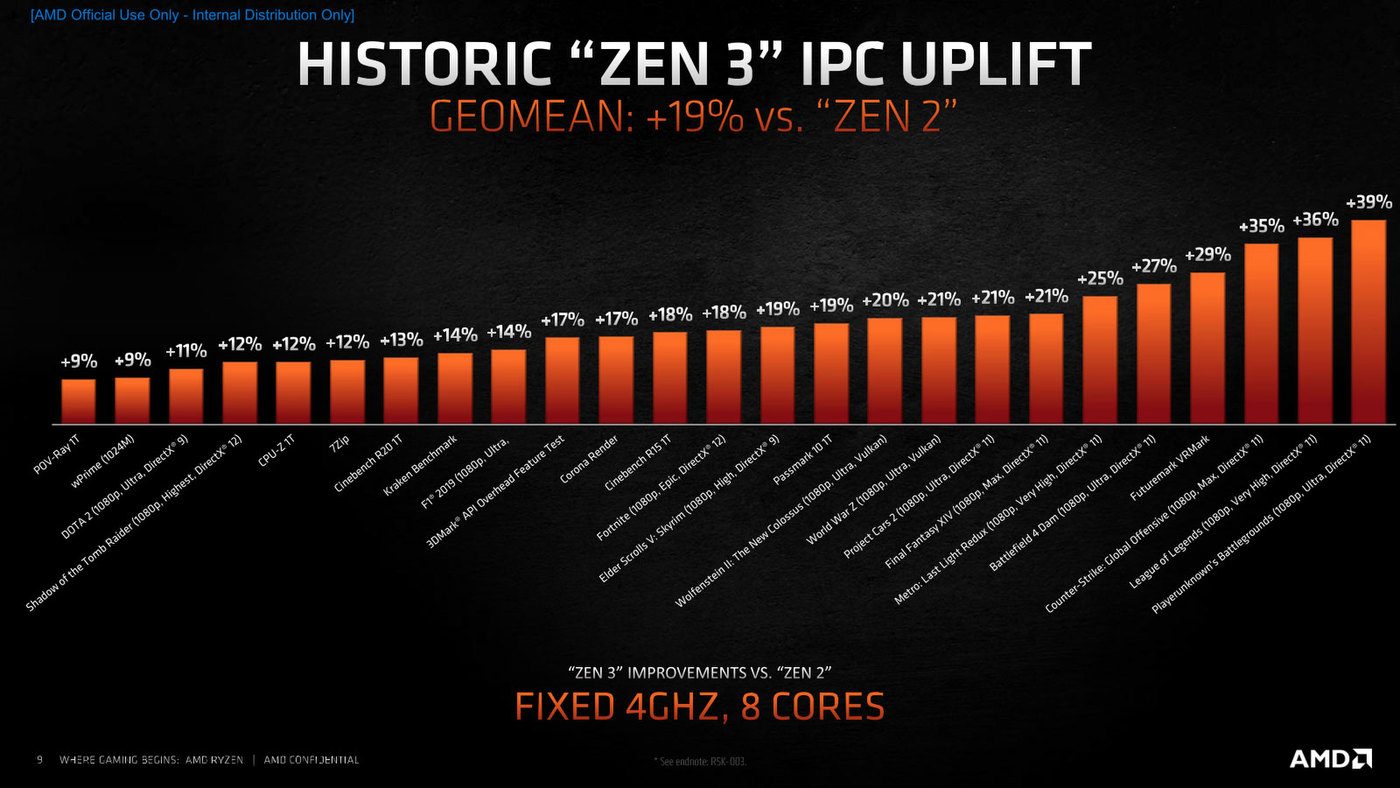
IPCは平均19%向上したという。POV-Rayの9%アップから、PUBGの39%まで向上率はさまざまだが、幾何平均を取ると19%という数字になる
ちなみにZen 3における主要なバッファサイズやレイテンシーの比較が下の画像である。L3キャッシュのみ、レイテンシーが39→46と増えているが、これはCCXが8コアとなり、32MBのL3が共有になった=Tagの検索により時間がかかるようになったことを考えれば無理ないところだろう。
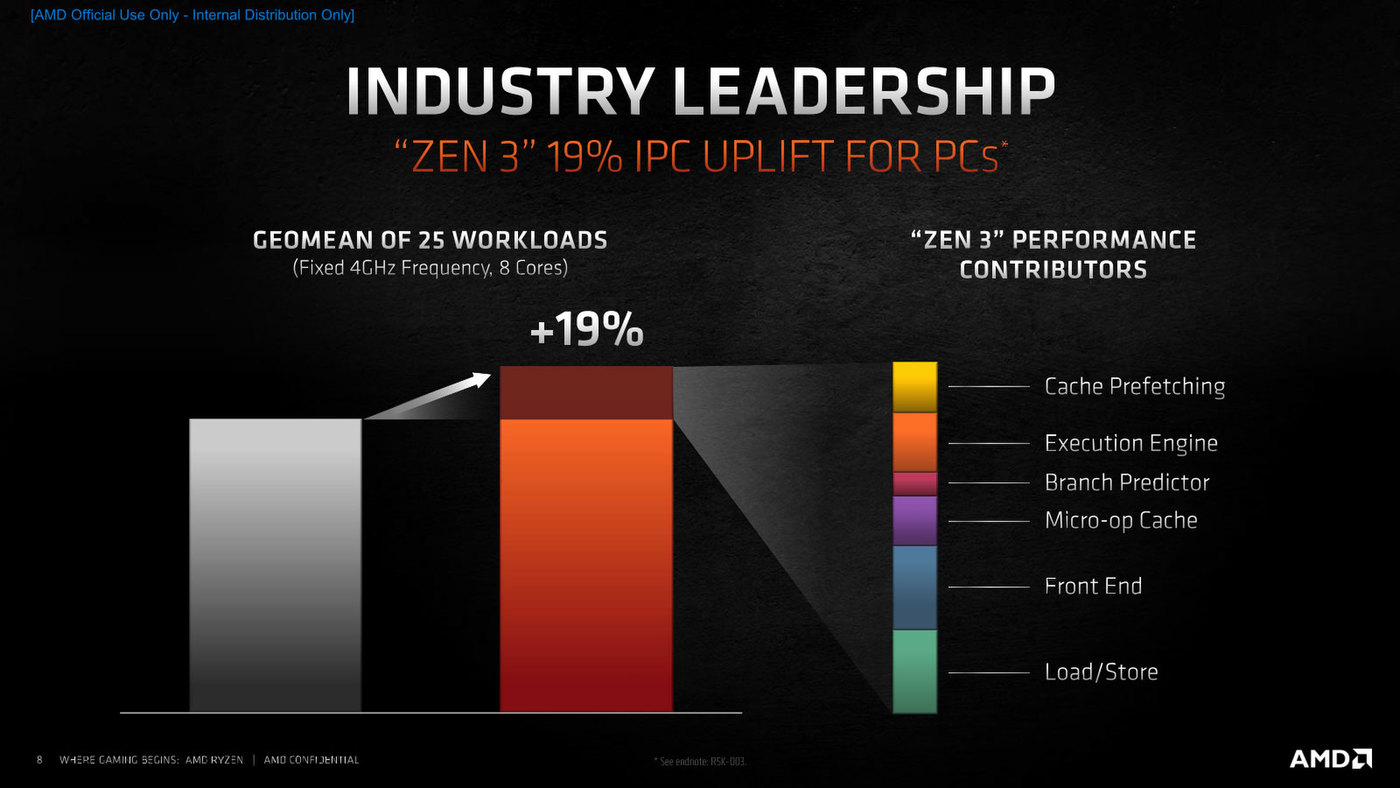
Zen 3における主要なバッファサイズやレイテンシーの比較。FADD/FMUL/FMAのみ、バッファサイズではなく実行のレイテンシーであるので注意
またCCXが8コア単位になったということは、それだけコア間の調停にも時間がかかることになる。ただそうしたペナルティーを払っても、ユニファイドL3キャッシュの効果が大きいのはKTU氏のレビューにある「コア間レイテンシーを確認する」でも偲ばれる。
このテストはコアというかスレッド間の通信に要するレイテンシーなので、L3アクセスのレイテンシーそのものではないのだが、スレッド間通信がL3経由で行なわれることを考えると、従来同じダイ上であっても異なるCCX同士では70ナノ秒以上かかっていたのが、25~27ナノ秒でアクセスできるようになったことの効果は大きいだろう。
これだけいろいろ盛り込みつつ、実はプロセスはN7+ではなくN7のままだった、というのがこれまた驚きである。つまりプロセス変更による性能向上やトランジスタ密度向上の恩恵には一切預かっていないわけだ。
AMDは現時点ではZen 3のダイサイズなどを発表していないが、早くもRyzen 5000シリーズを分解してダイサイズを測定した方がおられる。
Matisse (Zen2) vs Vermeer (Zen3) pic.twitter.com/Ic8Znyltql
— RetiredEngineer® (@chiakokhua) November 6, 2020
彼の測定によれば、Zen 2のCCDは7.43×10.31mmでおおむね76.6mm2、Zen 3のCCDは7.43×11.36mmで84.4mm2とされるが、ただ彼はAMD筋の数字としてZen 2が74mm2で39億トランジスタ、Zen 3は80.7mm2で41.5億トランジスタという数字も挙げており、どちらかというとこちらの方がリアルに近い気もする。
どちらにせよ、ダイそのものは良く似てはいるものの、かなりの部分が再設計され、より高い効率で動作するようになった。ただダイサイズの増分はごくわずかなので、(パッケージそのものは再設計されたと思うが)、既存のAM4に問題なく収まったというわけだ。
以上のことから、Zen 3は筆者の予想よりもはるかに手が入ったものであり、しかも将来のヘッドルームを十分持たせた設計であった。4命令/サイクルのデコーダーのままでここまで性能が引き上げられるのであれば、これを5命令/サイクルにしたらさらに性能が上がるだろう。
Zen 4は来年、5nmプロセスでの投入になるが、この延長で言えばインテルのGolden Coveとも良い勝負になりそうである。